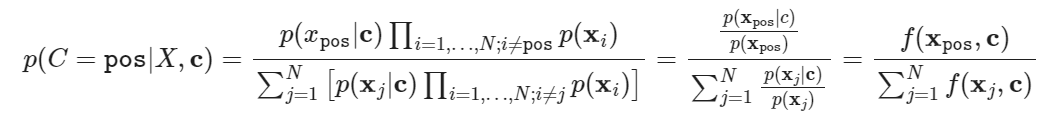Reference from : https://lilianweng.github.io/posts/2021-05-31-contrastive/#contrastive-loss
Contrastive Representation Learning
The goal of contrastive representation learning is to learn such an embedding space in which similar sample pairs stay close to each other while dissimilar ones are far apart. Contrastive learning can be applied to both supervised and unsupervised settings
lilianweng.github.io
Contrastive Training Objectives
1. Contrastive Loss (Chopra et al. 2005)

$\epsilon$ is a hyperparameter, defining the lower bound distance between samples of different classes.
: Loss that converge distance of Postive sample to 0 and Negattive sample to $\epsilon$.
2. Triplet Loss (Schroff et al. 2015)


$x^+$ is positive sample, $x^-$ is negative sample.
Margin parameter $\epsilon$ is the minimum offset between distances of similar and dissimilar pairs.
L2 norm distance, which the distance of the positive sample converge to zero and negativ sample to $\epsilon$.
It minimizes the loss on the pair of negative and postive samples at the same time.
3. Lifted Structured Loss (Song et al. 2015)
Utilize all the pairwise edges within one training batch for computational efficiency.



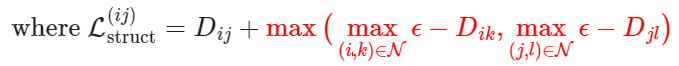


4. Multi-Class N-pair loss (Sohn 2016)
Generalize triplet loss to include multiple negative samples.

What happens if the network outputs constant output?
If we sample negative samples per class the loss is similar to the multi-class logistic loss (i.e., softmax loss)
https://www.youtube.com/watch?v=68dJCDyzB0A
https://junia3.github.io/blog/InfoNCEpaper
Welcome to JunYoung's blog | Simple explanation of NCE(Noise Contrastive Estimation) and InfoNCE
해당 내용은 Representation Learning with Contrastive Predictive Coding에서 소개된 InfoNCE를 기준으로 그 loss term의 시작에 있는 InfoNCE에 대해 간단한 설명을 하고자 작성하게 되었다. 논문링크 InfoNCE는 contrastiv
junia3.github.io

Use softmax transformation, we caculate cross entropy loss based on the vocabulary size($V$). Which the training function only considers the actual target word.

Through this denominator we are able to get non-zero gradient term. Where we all having noisy training
5. NCE : Noise Contrastive Estimation (Gutmann & Hyvarinen , 2010)
A method for estimating parameters of a statistical model
The softmax function comes with computational limitations for large amount of classes.
The Noise Contrastive Estimation (NCE) metric intends to differentiate the target data (word) from noise samples using a logistic regression classifier.
Given an input word $w_I$ the correct output word is $w$. And we sample $N$ other words from the noise sample distribution $Q$, denoted as $\hat{w_{i}}$.



6. InfoNCE : (Contrastive Predictive Coding; van den Oord, et al. 2018)
Inspired by NCE, uses categorical cross-entropy loss to identify the positive sample amongst a set of unrelated noise samples.
Positive sample should be drwon from the conditional distribution $p(x|c)$ and $N-1$ negative samples are drawn from the proposal distribution $p(x)$, independent from the context $c$.